article
AI Ruined My App
A cautionary tale about letting the machine drive
13 min read
Mar 9, 2026

The road to production
Falling Asleep at the Wheel
Well, let me tell you what really happened. I fell asleep at the wheel. Sad to say that literally has happened before; however, this time it wasn't a near death experience. Read Program Your Life for details on that one. Yeah, this time it only cost me a few days and the postponement of ToLive.ai release date.
What I mean when I say that I fell asleep at the wheel is a cautionary tale. AI is a tool. You can look at it as a riding lawn mower (I love to do yard work). You can sit on the mower and let it rip. It'll run over everything in its path and try to cut everything in it. But there's a reason it has a steering wheel or control arms (in the case of a zero turn).
Building with AI
I used AI to code the entire ToLive.ai application. But that's it. It did not make core architectural decisions. It did not tell me how to shape or relate my data. But that's just where I got messed up. You see, although I've been using AI since the second week that ChatGPT was released and using it to write production code, I had never had it create something without my close attention to it.
My pattern was broken with the new tooling. It took me a while to get to my go-to approach. Over the past couple of years, I've been heads down at work, at home with my children, in a book, or a late-night group meeting for B-School (completing my MBA at Tech). So, I was still copying and pasting from Claude and ChatGPT. I tried Cursor but I didn't like it for whatever reason. I tried Copilot but I still didn't like that either. Enter Claude Code.
Another Senior Engineer and I were having a conversation on AI tooling in October of 2025, and he mentioned how he was using Claude to write everything. He's an early adopter and at the time had way more time to do exploratory stuff. Me, I was just getting by with 6–10.5 credit hours on my plate Fall, Spring and Summer, and getting promoted while learning on the job. It was insane. But I managed to make all A's and B's and save Pluralsight $60M in B2B ARR. You have to have both hard and soft skills to do that type of thing.
The Breakthrough
So now's my time, right? I'm thinking I just got this DGX Spark. I can use AI to teach me how to build AI. I was blown away at how good Claude Code is at many things concerning my daily work. It eliminated my coding. I mean, this thing can write code better and faster than any human I know, and I know some truly talented engineers.
Claude was helping me to implement some long-needed features, cleanup, and upgrades to my personal website that I simply did not have the time to code myself. I mean something that would have taken hours, or a few days was now done in minutes.
In the weeks following, as I became more comfortable using it I decided to use it for bigger things, bigger applications. I used it to help me build my “talking head”—the speech avatar that I use to post on LinkedIn. I used it to code ToLive.ai which was a byproduct of the work from the speech avatar.
The Critical Mistake
So, I started from nothing. An empty project and all I had was a goal in mind. I did a decent job of system architecting the initial app and I planned out what the data would look like. I decided on all my technologies. I even implemented some examples. You can see Example MCP and Example RAG for some of the core pieces of ToLive.ai. So, what jammed me up?
As I was building, I ignored how Claude was relating my data (to process [“join” for SQL people] it based on a “primary” and “foreign” key). That means I ignored how things were being pulled together in queries. Another big mistake Claude would make was that it would do two queries and then in my TypeScript loop over it to aggregate it. This all should have been done on the database level.
The AI was not “thinking” “let me use the database's compute to aggregate this because it can aggregate hundreds of documents in a fraction of a second.” The AI was not thinking at all. It was just guessing what the next thing should be based on what it had seen before.
And what are the query and in-app aggregation going to look like as the app scales? Best case scenario, I'm adding another O(n) operation to my code. No, it wasn't “thinking” like that. I had to instruct it based on how I knew it should go. Anyway, typically in MongoDB when you aggregate data you use the _id of the document that you want to relate the other document to. For example, in ToLive.ai we have sessions, messages, and users amongst other collections.
Data Schema Example
Here's what the problem was. Instead of using the _id field (the primary key with built-in indexing) to aggregate documents, Claude used cognito_sub (the AWS Cognito authentication identifier) across eight of my twelve collections. And at this time, the app was nearly ready for production. I had to stop and refactor.
Sessions Collection:
{
"_id": ObjectId("69a8d0a4b1535d05c07c2aa9"),
"user_id": ObjectId("69a8ad78a408ec5f39b954a9"),
"org_id": null,
"shared": false,
"title": "are you working?",
"created_at": Date("2026-03-05T00:39:00.374Z"),
"updated_at": Date("2026-03-05T00:46:10.237Z"),
"metadata": {},
"deleted": false
}Messages Collection:
{
"_id": ObjectId("69a8d0a4b1535d05c07c2aab"),
"session_id": ObjectId("69a8d0a4b1535d05c07c2aa9"),
"role": "user",
"content": {
"c": "TXl8f/byjxEy6ePW2svLmA==",
"iv": "GiAUYcGQwIl0FBSN",
"tag": "yPVCwm8OGPo9YZOiUlK95g==",
"v": 1
},
"created_at": Date("2026-03-05T00:39:00.589Z"),
"rag_context": null
}User Collection:
{
"_id": ObjectId("69a8ad78a408ec5f39b954a9"),
"cognito_sub": "2479e4d8-9171-40d4-e832-0a31c3fa6f75",
"email": "some@gmail.com",
"given_name": "naeem",
"family_name": "gitonga",
"tier": "org",
"trial_used_at": Date("2026-03-05T00:43:16.594Z"),
"created_at": Date("2026-03-04T22:09:09.966Z"),
"updated_at": Date("2026-03-09T04:02:50.245Z"),
"metadata": {
"timezone": "America/New_York"
},
"stripe_customer_id": "cus_U6cCDyByQIsYjT",
"stripe_subscription_id": "sub_1T2Q0VCBU3burpfoYnpOfREO",
"subscription_status": "trialing",
"terms_of_agreement_signed": true
}Those three documents represent the current state. You can see how each document is related to the next via the _id. It's best to use the _id when you can because it comes with indexing already, thereby making it very efficient when querying. It's the primary key so to speak. And when aggregating (or “joining”) it's perfect for relating your documents across collections. But that's not what Claude did. It was my guidance and nearly having to scrap two weeks' worth of work to use this pattern.
The Real Problem
Well Claude decided to use the cognito_sub property instead. The cognito_sub is the identifier from AWS Cognito (what I use for authentication). Well it's not that bad, right? I thought it was blasphemous, not to be vain. But seriously, a string that is splattered all across documents causing me to need to create unnecessary indexes. And what if one day I decided to move to a different Auth engine? What if I decided to role my own auth? Would I be stuck with this cognito_sub that I no longer wanted or needed? Yup, I sure would have had I not stopped right where I was at and fix the issue. Eight of my twelve collections depended on this cognito_sub to relate documents back to users. I almost cried when I realized the mistake I had made. I came to doubt the abilities of the AI. And I questioned whether I had overrelied on it.
The Lesson Learned
Most importantly, I learned a lesson. The lesson is to not depend on the machine at all and not to trust it to do the things that it does well, well. Planning your data story is not something that it will do well. Given the correct prompt, it may get you 85% of the way there. But is that 15% going to cost you hundreds of hours to refactor? If it does, AI just got you to a roadblock just that much quicker. I even thought to myself, maybe I do need to start coding more by hand again.
And that's when I realized. Claude is a really good Junior engineer. Hell, it may even be mid-level. It is like Rain Man (for those of you that remember the Tom Cruise and Dustin Hoffman movie from the late 80s). It can remember and fetch from context everything, rattle off numbers, come up with an algorithm in seconds that would take the best human engineer at least minutes to write. But let it run, and it'll soon hit a wall or fall flat on its proverbial face.
It was my come to Jesus moment, if you will. I mean geez, here I am with this amazing tool and it can't do everything for me. You mean I actually have to be a software engineer to get maximum benefit out of it? Yup, and you do too. Claude will get you going but it's like a former co-worker and I agreed on when talking about ChatGPT in the early days. It will get you about 85% of the way there but your skills have to bring it home plate.
Architecture in Production
Here's what the current architecture of ToLive.ai looks like.
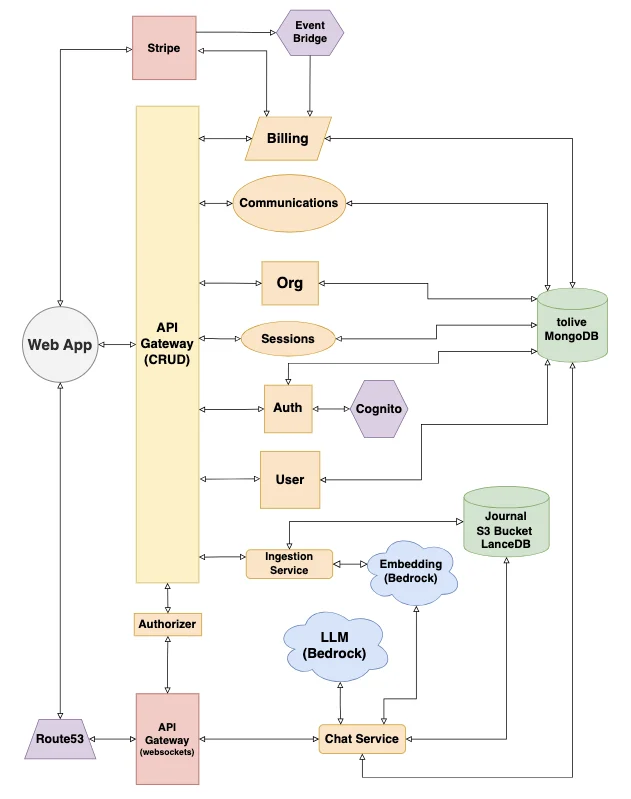
ToLive.ai Architecture Overview
I was able to get to production on March 6, 2026. It was a successful launch and I continue to roll out new features. At the speed with which I can produce work, you may see new features daily.
So, technically AI didn't ruin my app. I did. I got lax, comfortable; I paid the price. And I had to fix it. I had to rely on my principles, my design patterns, my learned best practices. All of which can be discussed, validated, or vetted using the LLM but you have to have this knowledge, gained through lived experience, years of software engineering. So, is AI going to replace software engineers—not this year at least.
The Future of Software Engineering
Computers are still garbage in, garbage out even in probabilistic systems. Skilled engineers are going to be needed in charge of driving these machines same as when driving a locomotive. The things to focus on now may not be coding. It may be system design and architecture. Being an expert in the algorithms may not be as important as having the understanding of where they are applied. We need to be well versed in best practice. However, understanding the programming language is still super important. I could have had Claude build ToLive.ai in Java but I would not be as confident in it. I've shipped production Java while working at Honeywell back in 2021 but none since then. Juniors need to learn design patterns; they need to learn how to structure a project and keep things DRY. The hardest thing ever, they need to know how to name things (Claude often sucks at that too).
If you have taken anything away from this article, at least leave with this. AI is a tool, not a driver. If you subsequently slow down, that is better than starting over or creating a mountain of tech debt.
What's Next
The next thing to do is to make some updates for scaling more efficiently. Currently I'm using all serverless everything. But there are some queries that should hit the database a little less often. There are areas that we can have quick wins in regarding optimization which would make the app scale better by reducing the frequency of certain API calls, namely get sessions, get entries, and get orgs. Maybe I'll make that my next article. And I still need to give you guys an update on the observability story. I'm on a shoestring budget but I am using CloudWatch with AWS SNS for alerting.
Until next time, stay tuned! Hit the contact form with your thoughts. I want to know what you think about the subject. And make sure to subscribe to ToLive.ai. It's waiting for you.
I figured, if you made it this far you deserve a laugh. Don't be this guy above. Never let Claude drive. Always keep your hands on the wheel and your eyes on the road ahead.